万通智控称自主研发开发了 NLP 传感器,性价比具有明显优势,该公司目前经营现状如何?
机器视觉都有哪些品牌,性价比如何_工业机器视觉三大品牌
1、凌华科技
凌华科技(中国)有限公司,是台湾凌华科技集团在中国大陆设立的分公司。是一家致力于研究、制造基于PC技术的专业计算机、自动化数据量测系统及工业过程自动化控制设备的专业厂商。
几年来,凌华科技以专业的技术为各界的用户提供了高质量、经济化的量测与自动化产品及解决方案。
凌华科技在图像采集卡方面具有强大的科研实力,自行研发制造的产品被广泛应用在SCADA系统、工业、测量、智能机器,智能交通以及现代通讯系统、医疗设备、航天、军工等领域。
2、大恒图像
中国大恒(集团)有限公司北京图像视觉技术分公司简称为大恒图像,成立于1991年,总部在北京,是中国科学院下属企业。大恒图像的技术骨干主要来自中国科学院各研究单位,公司的产品和技术基础来源于中国科学院多年的技术积累,是将高新技术成果转化为产品的高科技企业。
大恒图像自成立之日起,一直坚持走以技术开发为主的发展道路,一直致力于图像视觉领域的研究开发,建立了技工贸一体化的结构,连续十五年被中关村科技园区认定为高新技术企业。
在国内,大恒图像是首屈一指的专业视频图像处理设备供应商,同时也是著名的图像应用系统集成商和解决方案提供商。
3、视觉龙
深圳市视觉龙科技有限公司是一家由归国留学人员创办的高科技企业,公司成立于2002年9月,在深圳、常州和嘉兴分别设有公司。成立以来,公司一直致力于机器视觉产品的应用开发、嵌入式机器视觉系统的研发、生产以及销售。
视觉龙专业涵盖非接触式测量(含机器视觉、位移测量等)、自动化控制、精密机械、电子、工控软件等诸多重要领域。可以提供机器视觉单元、镜头、光源等硬件及软件方面的支持和配合。
应用前景:在包括汽车制造、制药、电子、包装、印刷、烟草、日化、建材、制币、制卡等在内的几乎所有的现代工业自动化生产中,涉及到各种各样的检验生产监视和零件识别应用,如汽车零件批量加工,端子尺寸检测,SMT装配,IC的字符识别等等,通常这种带有高度重复性和智能性的工作只能用人的肉眼来完成,但有些时候,如微小的尺寸要做到精确快速测量,形状匹配,颜色识别等,人们根本无法用肉眼连续稳定地进行,其他物理传感器也难以有用武之地。视觉龙科技作为一间专门为高要求用户提供图像处理和机器视觉软件及全面解决方案的公司,一直致力于机器视觉自动化的推广,在业内已具有骄人的业绩和口碑,为推动以上工业发展做出了巨大的努力。
4、凌云光子
凌云光子技术集团是致力于光通信()、CCD&CMOS数字成像技术和机器视觉领域(&)的专业技术集团公司。
集团总部位于北京,下设北京凌云光视数字图像技术有限公司、北京凌云光子技术有限公司,上海凌云天博光电技术有限公司和香港分公司,并在上海、深圳两地设有办事处。公司现有博士11名,硕士120多名,其中包括多名在海外留学多年的光通信专家和国内图像与机器视觉领域的知名学者。目前已成长为拥有580多名员工、从事光通信和图像领域的市场营销与技术开发的高科技专业技术公司。是国内最早涉足光纤通信器件及光纤有线电视领域的高科技企业之一。
公司为Bookham、Fujikura、U2T、TeraXion、VPIsystems、Avensys、EXFO等四十多家世界著名的专业技术公司在中国做产品推广、应用技术支持、市场拓展和渠道建设等工作,公司专注于光通信EDFA、40Gb/sDWDM光传输、100Gb/sDWDM光传输、ROADM、偏振、光纤激光器、FBG传感、光接入网传输等多个应用领域,为广大用户提供从软件模拟、各种关键元器件,到测试仪表在内的整套产品解决方案,且逐渐开始在光通信领域开展自主研发及生产。
5、康视达
康视达自动化科技有限公司是一家专业从事机器视觉光源、机器视觉系统集成、研发和服务的高新科技企业。公司立足于机器视觉和工业自动化领域,专注于机器视觉和运动控制的完美结合,全力打造视觉高端产品。
康视达研发LED机器视觉光源,形成环形光源、条形光源、线扫描光源、面光源、圆顶无影光源、平面无影光源、同轴光源、点光源、AOI设备专用光源、锡膏印刷机专用光源等众多系列,拥有多项专利技术。机器视觉光源是康视达公司的核心产品。
康视达代理国内外知名品牌的工业产品,包括:Cognex、NI、Panasonic等智能相机,SENTECH、Teli、Hitachi、工业相机,Computar、VST、Navita、Myutron工业镜头,以及NI图像采集卡,MCC数据采集卡,HALCON图像处理软件等。
6、三姆森光电科技
东莞三姆森光电科技有限公司成立于2005年,是专门研究图像处理及自动化运用的高科技企业,从事机器视觉检测,集自动化控制系统设计、开发、销售的高科技公司。主要业务有:自动化系统,连接器检测,CCD平整度检测,机器视觉系统,包装检测系统,自动化在线检测,尺寸检测,外观检测,视觉软件开发,视觉配件。
公司有三大视觉系统,1、PC视觉系统,它的主要特点是:可以根据客户的要求“量身定做”,性价比非常高,软件操作非常简便,功能强大,我们公司在电子行业应用的非常广泛,尺寸测量,定位,字符识别,外观等等都可以检测。2、和日本合作开发的专门用于外观检测的SA外观检测系统,专门针对各种外观缺陷设计开发的一款系统,一台处理器最多可以连接四个相机,因采用了独立的矢量软件算法,在检测外观缺陷的项目上,有非常大的优势。3、代理美国COGNEX的智能视觉系统,主要应用在一些高速高精度的检测项目上,安装应用都比较简单。
7、OPT
OPT是奥普特自动化科技有限公司的简称,该公司主要从事机器视觉产品的研发生产销售,目前是中国机器视觉光源制造厂商。为客户提供视觉定位、光学检测、图像分析、图像测量等方面的系统开发与集成解决方案。OPT销售及服务网络覆盖全球20多个国家和地区,拥有30多家授权代理商。
公司目前主要光源产品有环形光源、同轴光源、背光源、条形光源、组合条形光源、点光源、球积分光源、线形光源、AOI检测专用光源、SMT行业对位光源十大系列。配套有数字式光源控制器、模拟式光源控制器、增亮模块、数字增亮一体控制器、模拟增亮一体控制器。
8、凯瑞斯
东莞凯瑞斯自动化科技有限公司位于东莞市莞城科技园,注册资金100万,是一家由留学回国人员创办的高新科技企业,依托华南理工大学、华中科技大学、成都电子科技大学等国内知名大学,成功聚集了一批高端留学人员和高级技术人才,立足于机器视觉和工业自动化领域,专业从事机器视觉光源、机器视觉系统及工业机器人的研发和技术服务,通过机器视觉和运动控制的完美结合,全力打造视觉高端产品。
如何建立企业文化?
建立企业文化 一、 完善企业管理制度 一个缺乏规范管理制度的企业如何奢谈文化?文化是软性的东西,必须有硬性的制度保障,而且制度应该视为企业文化的重要组成部分。鉴于该集团公司成立时间较短,一些制度尚欠缺或不够完善、或者已经不合时宜(部分继承原母集团公司的制度体系)。为此,集团组织主要的职能部门开展了为期超过半年的制度重建工作。通过完善集团统一的制度并强化实施,加强了集团的统一管理和集团主要职能部门的权威和管理规范性。制度只是死的文字条款,而如何有效执行才是关键,该项工作取得集团高层领导的大力支持,因而为后期的推行减少了阻力。同时,由于完善的制度从而逐渐改变过去的人治色彩,公司各项管理工作逐渐规范国内比较好的大数据 公司有哪些
“大数据”近几年来可谓蓬勃发展,它不仅是企业趋势,也是一个改变了人类生活的技术创新。大数据对行业用户的重要性也日益突出。掌握数据资产,进行智能化决策,已成为企业脱颖而出的关键。因此,越来越多的企业开始重视大数据战略布局,并重新定义自己的核心竞争力。

国内做大数据的公司依旧分为两类:一类是现在已经有获取大数据能力的公司,如百度、腾讯、阿里巴巴等互联网巨头以及华为、浪潮、中兴等国内领军企业,做大数据致店一叭柒叁耳领一泗贰五零,涵盖了数据采集,数据存储,数据分析,数据可视化以及数据安全等领域;另一类则是初创的大数据公司,他们依赖于大数据工具,针对市场需求,为市场带来创新方案并推动技术发展。其中大部分的大数据应用还是需要第三方公司提供服务。

越来越多的应用涉及到大数据,这些大数据的属性,包括数量,速度,多样性等等都是呈现了大数据不断增长的复杂性,所以,大数据的分析方法在大数据领域就显得尤为重要,可以说是决定最终信息是否有价值的决定性因素。基于此,对大数据进行分析的产品有哪些比较倍受青睐呢?

而在这里面,最耀眼的明星当属Hadoop,Hadoop已被公认为是新一代的大数据处理平台,EMC、IBM、Informatica、Microsoft以及Oracle都纷纷投入了Hadoop的怀抱。对于大数据来说,最重要的还是对于数据的分析,从里面寻找有价值的数据帮助企业作出更好的商业决策。下面,我们就来看看以下十大企业级大数据分析利器吧。

随着数据爆炸式的增长,我们正被各种数据包围着。正确利用大数据将给人们带来极大的便利,但与此同时也给传统的数据分析带来了技术的挑战,虽然我们已经进入大数据时代,但是“大数据”技术还仍处于起步阶段,进一步地开发以完善大数据分析技术仍旧是大数据领域的热点。

在当前的互联网领域,大数据的应用已经十分广泛,尤其以企业为主,企业成为大数据应用的主体。大数据真能改变企业的运作方式吗?答案毋庸置疑是肯定的。随着企业开始利用大数据,我们每天都会看到大数据新的奇妙的应用,帮助人们真正从中获益。大数据的应用已广泛深入我们生活的方方面面,涵盖医疗、交通、金融、教育、体育、零售等各行各业。

可视化分析
大数据分析的使用者有大数据分析专家,同时还有普通用户,但是他们二者对于大数据分析最基本的要求就是可视化分析,因为可视化分析能够直观的呈现大数据特点,同时能够非常容易被读者所接受,就如同看图说话一样简单明了。

2. 数据挖掘算法
大数据分析的理论核心就是数据挖掘算法,各种数据挖掘的算法基于不同的数据类型和格式才能更加科学的呈现出数据本身具备的特点,也正是因为这些被全世界统计
学家所公认的各种统计方法(可以称之为真理)才能深入数据内部,挖掘出公认的价值。另外一个方面也是因为有这些数据挖掘的算法才能更快速的处理大数据,如
果一个算法得花上好几年才能得出结论,那大数据的价值也就无从说起了。

3. 预测性分析
大数据分析最终要的应用领域之一就是预测性分析,从大数据中挖掘出特点,通过科学的建立模型,之后便可以通过模型带入新的数据,从而预测未来的数据。

4. 语义引擎
非结构化数据的多元化给数据分析带来新的挑战,我们需要一套工具系统的去分析,提炼数据。语义引擎需要设计到有足够的人工智能以足以从数据中主动地提取信息。
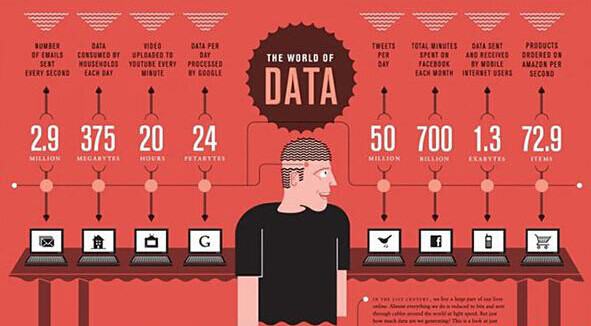
5.数据质量和数据管理。 大数据分析离不开数据质量和数据管理,高质量的数据和有效的数据管理,无论是在学术研究还是在商业应用领域,都能够保证分析结果的真实和有价值。
大数据分析的基础就是以上五个方面,当然更加深入大数据分析的话,还有很多很多更加有特点的、更加深入的、更加专业的大数据分析方法。

大数据的技术
数据采集: ETL工具负责将分布的、异构数据源中的数据如关系数据、平面数据文件等抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础。
数据存取: 关系数据库、NOSQL、SQL等。
基础架构: 云存储、分布式文件存储等。
数据处理:
自然语言处理(NLP,Natural Language
Processing)是研究人与计算机交互的语言问题的一门学科。处理自然语言的关键是要让计算机”理解”自然语言,所以自然语言处理又叫做自然语言理解也称为计算语言学。一方面它是语言信息处理的一个分支,另一方面它是人工智能的核心课题之一。
统计分析:
假设检验、显著性检验、差异分析、相关分析、T检验、 方差分析 、
卡方分析、偏相关分析、距离分析、回归分析、简单回归分析、多元回归分析、逐步回归、回归预测与残差分析、岭回归、logistic回归分析、曲线估计、
因子分析、聚类分析、主成分分析、因子分析、快速聚类法与聚类法、判别分析、对应分析、多元对应分析(最优尺度分析)、bootstrap技术等等。
数据挖掘:
分类 (Classification)、估计(Estimation)、预测(Prediction)、相关性分组或关联规则(Affinity
grouping or association rules)、聚类(Clustering)、描述和可视化、Description and
Visualization)、复杂数据类型挖掘(Text, Web ,图形图像,视频,音频等)
模型预测 :预测模型、机器学习、建模仿真。
结果呈现: 云计算、标签云、关系图等。

大数据的处理
1. 大数据处理之一:采集
大数据的采集是指利用多个数据库来接收发自客户端(Web、App或者传感器形式等)的
数据,并且用户可以通过这些数据库来进行简单的查询和处理工作。比如,电商会使用传统的关系型数据库MySQL和Oracle等来存储每一笔事务数据,除
此之外,Redis和MongoDB这样的NoSQL数据库也常用于数据的采集。
在大数据的采集过程中,其主要特点和挑战是并发数高,因为同时有可能会有成千上万的用户
来进行访问和操作,比如火车票售票网站和淘宝,它们并发的访问量在峰值时达到上百万,所以需要在采集端部署大量数据库才能支撑。并且如何在这些数据库之间
进行负载均衡和分片的确是需要深入的思考和设计。

2. 大数据处理之二:导入/预处理
虽然采集端本身会有很多数据库,但是如果要对这些海量数据进行有效的分析,还是应该将这
些来自前端的数据导入到一个集中的大型分布式数据库,或者分布式存储集群,并且可以在导入基础上做一些简单的清洗和预处理工作。也有一些用户会在导入时使
用来自Twitter的Storm来对数据进行流式计算,来满足部分业务的实时计算需求。
导入与预处理过程的特点和挑战主要是导入的数据量大,每秒钟的导入量经常会达到百兆,甚至千兆级别。

3. 大数据处理之三:统计/分析
统计与分析主要利用分布式数据库,或者分布式计算集群来对存储于其内的海量数据进行普通
的分析和分类汇总等,以满足大多数常见的分析需求,在这方面,一些实时性需求会用到EMC的GreenPlum、Oracle的Exadata,以及基于
MySQL的列式存储Infobright等,而一些批处理,或者基于半结构化数据的需求可以使用Hadoop。
统计与分析这部分的主要特点和挑战是分析涉及的数据量大,其对系统资源,特别是I/O会有极大的占用。
4. 大数据处理之四:挖掘
与前面统计和分析过程不同的是,数据挖掘一般没有什么预先设定好的主题,主要是在现有数
据上面进行基于各种算法的计算,从而起到预测(Predict)的效果,从而实现一些高级别数据分析的需求。比较典型算法有用于聚类的Kmeans、用于
统计学习的SVM和用于分类的NaiveBayes,主要使用的工具有Hadoop的Mahout等。该过程的特点和挑战主要是用于挖掘的算法很复杂,并
且计算涉及的数据量和计算量都很大,常用数据挖掘算法都以单线程为主。
在国内智能家居的十大牌子里,哪个的经销商比较好做?
2022智能锁十大品牌排行榜,是中国科技网数据研究,重磅推出的十大智能锁品牌排行榜,智能锁10大品牌榜。十大品牌名单展示各行业数据前10强,由中国科技网品牌数据研究部门通过资料收集整理,并基于大数据统计及人为根据市场和参数条件变化分析研究而得出,是大数据、云计算、数据统计真实客观呈现的结果。名单以企业实力、品牌荣誉、网络投票、网民口碑打分、企业在行业内的排名情况、企业获得的荣誉及奖励情况等为基础,通过本站特有的计算机分析模型对广泛的数据资源进行采集分析研究,综合了多家机构媒体和网站排行数据,原始数据来源于信用指数以及几十项数据统计计算系统生成的品牌企业行业大数据库,并由研究人员综合考虑市场和参企业为什么要做数字化转型,如何进行数字化转型?
由社交媒体、移动设备、物联网和大数据引发的数字化趋势不仅改变了人们的生活方式也要求企业重新思考设计原来的运作模式。在现实生活中,数字化是可以感知的,比如,我们上网浏览新闻时,就是媒体内容的数字化。数字化进程的演进使得“数字化”已经跳脱了二进制化的概念,成为一种人类与世界互动的新方式。如今我们生活在一个数据驱动发展的时代,不能顺应时代发展进步的企业就会落后和淘汰。一个新技术时代应运而生,一个数据主导的数字企业时代也必将应声而至。 数字化转型是企业顺应时代的必然要求 早在1996年Nicholas Negroponte就在被誉为二十世纪信息技术及理念发展圣经的《数字化生存》中预言到了今天的数字化时相关文章

国药现代控股子公司药品注射用高纯
国药集团的药品上市许可持有人是控股子公司国药集团致君(深圳)坪山制药有限公司(简称“国药致君坪山”)收到国家药监局核准签发的《药品补充申请批准通知书》,同意奥美沙坦酯氨氯
2024-05-07
国资企业和私企各自有什么优势?
国企与外企、私企的优缺点?国企优势1、稳定。如果有编制,怎么搞都不会有辞退的危机,心里十分安定。对于家境殷实的小伙伴真的是个好出处。2、试错机会多,对新人有培养的耐心。国
2024-05-06
初创企业怎样制定合适的发展战略?
适合于初创企业的策略有( )适合初创企业的策略有:立足细分市场、创新思维、投资于优质人才、加强市场营销、控制成本。1、立足细分市场:初创企业不可能在市场上立即占据主导地
2024-05-06-
国民技术称量子密码技术是公司密切
如何利用信息技术提升企业竞争力1.激烈竞争使企业暴露的问题 在七八十年代,许多公司在发展信息技术上投入大量财力,但却很难看到生产力从谷底回升,甚至对信息技术使用得越多,企业
2024-05-06 
微信营销适用于哪些类型的企业?
企业微信营销哪些行业适合做微信营销虽然成为了最热门的商业话题之一,但这并不代表任何行业都适合做微信营销。本章将会告诉大家,如何来判断自己的企业是否适合微信营销。同时
2024-05-06
上海市互联网证券信息服务企业合规
什么是可转债,为什么最近这么流行?4.1亿的借款+预期权益+贾跃亭无限责任担保的“擦边球”产品,以年化15%高息层层分销散户,目前无法兑付引发诉讼。总额5.3亿美元的乐视移动“Pre
2024-05-06
帮忙解答如下这道《企业运营管理》
企业运营管理部门的主要职责是什么?营运管理部作为一个综合职能部门,对公司经营管理的全过程进行计划执行和控制。
2024-05-05
营运部的职责:营运部对公司的各个门店日常经营行为及业务、
岱勒新材称产品价格在年内已有阶段
在市场营销学中,产品生命周期是什么?产品生命周期(product life cycle),简称PLC。是指产品的市场寿命,即一种新产品从开始进入市场到被市场淘汰的整个过程,分为介绍期(Introduction
2024-05-05
企业盈利能力受哪些因素影响?
盈利能力影响因素摘要:企业的盈利能力是企业发展的重要指标,它受到多种因素的影响,包括市场状况、行业环境、企业结构、管理方式、技术水平、财务状况等。本文将对这些影响因素
2024-05-05