如何获取金融数据?
想要金融类数据,应该如何收集?
金融大数据平台的搭建和应用是两个部分,对于金融大数据平台来说,这两个部分都很重要。
所以以下的部分我们从大数据平台和银行可以分析哪些指标这两个角度来阐述。
一、大数据平台
大数据平台的整体架构可以由以下几个部分组成:
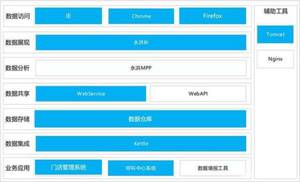
从底层逐步往上,如图所示表示这么几个环节:
一、业务应用:其实指的是数据采集,你通过什么样的方式收集到数据。互联网收集数据相对简单,通过网页、App就可以收集到数据,比如很多银行现在都有自己的App。
更深层次的还能收集到用户的行为数据,可以切分出来很多维度,做很细的分析。但是对于涉及到线下的行业,数据采集就需要借助各类的业务系统去完成。
二、数据集成:指的其实是ETL,指的是用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。而这里的Kettle只是ETL的其中一种。
三、数据存储:指的就是数据仓库的建设了,简单来说可以分为业务数据层(DW)、指标层、维度层、汇总层(DWA)。

四、数据共享层:表示在数据仓库与业务系统间提供数据共享服务。Web Service和Web API ,代表的是一种数据间的连接方式,还有一些其他连接方式,可以按照自己的情况来确定。
五、数据分析层:分析函数就相对比较容易理解了,就是各种数学函数,比如K均值分析、聚类、RMF模型等等。
列存储让磁盘中的各个Page仅存储单列的值,并非整行的值。这样压缩算法会更加高效。进一步说,这样能够减少磁盘的I/O、提升缓存利用率,因此,磁盘存储会被更加高效的利用。
而分布式计算能够把一个需要非常大的算力才能解决的问题分成很多小部分,接着把这些部分给到许多计算机同时处理,然后把这些计算结果综合起来,得到最终的结果。
综合这两种技术,就能够大幅度提高分析环节的效率。Yonghong MPP可以说是目前在这两方面做的最出色的了。
六、数据展现:结果以什么样的形式呈现,其实就是数据可视化。这里建议用敏捷BI,和传统BI不同的是,它能通过简单的拖拽就生成报表,学习成本较低。国内的敏捷BI中,个人用户推荐Tableau,像银行这类的企业级需求推荐Yonghong BI 。
七、数据访问:这个就比较简单了,看你是通过什么样的方式去查看这些数据,图中示例的是因为B/S架构,最终的可视化结果是通过浏览器访问的。
二、银行数据分析体系如何搭建?
搭建一个数据平台可能是项目制的工作,在一段时间内会完成,但是搭建数据分析体系这件事却任重而道远。但是如果有人能在做产品的同时,将金融行业同类的数据应用经验也分享给你,帮助你去搭建数据分析体系,那就是真正的“良药”了。
下面分享一个YonghongTech帮助某大型银行数据服务平台建设的案例。
以客户在银行办理业务的行为路径,可以有这样几个主题,不同主题有对应的场景及其指标。

1.一个客户
客户主题:客户属性(客户编号、客户类别)、指标(资产总额、持有产品、交易笔数、交易金额、RFM)、签约(渠道签约、业务签约)组成宽表
2.做了一笔交易
交易主题:交易金融属性、业务类别、支付通道组成宽表。
3.使用哪个账户
账户主题:账户属性(所属客户、开户日期、所属分行、产品、利率、成本)组成宽表
4.通过什么渠道
渠道主题:渠道属性、维度、限额组成宽表
5.涉及哪类业务&产品
产品主题:产品属性、维度、指标组成宽表
如何使用八爪鱼采集金融界基金数据
1、创建金融界基金数据采集任务
2、创建文本循环
3、分页表格信息采集
4、基金数据采集及导出
1.创建金融界基金数据采集任务1)进入主界面,选择“自定义采集”2)将要上述采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
2.创建文本循环1)鼠标滑动到页底,然后选中“下一页”,提示框中选择“循环点击下一页”2)由于页面使用了ajax加载技术,需要对点击元素及翻页步骤设置ajax延时加载(ajax判断方法:打开流程图,找到翻页循环框,手动执行翻页,看网站有没有进行加载)在右侧的高级选项框中,勾选Ajax加载数据,选择合适的超时时间,一般设置3秒;最后点击确定。
3.分页表格信息采集l选中需要采集的字段信息,创建采集列表l编辑采集字段名称移动鼠标选中表格里任意一个空格信息,右键点击,如图所示,框中数据会被选中,变成绿色,点击右侧提示中点击“TR”选中数据当前一行的数据会被全部选中,点击“选中子元素右侧操作提示框中,查看提取的字段,可将不需要字段删除,点击“选中全部”点击“采集以下数据”
4.基金数据采集及导出采集完成后,会跳出提示,选择导出数据,选择合适的导出方式,将采集好的数据导出,这里我们选择excel作为导出为格式,一份完好的金融界基金数据就导出好了
如何用python 爬虫抓取金融数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一。鉴于此,我拾起了Python这把利器,开启了网络爬虫之路。
本篇使用的版本为python3.5,意在抓取证券之星上当天所有A股数据。程序主要分为三个部分:网页源码的获取、所需内容的提取、所得结果的整理。
一、网页源码的获取
很多人喜欢用python爬虫的原因之一就是它容易上手。只需以下几行代码既可抓取大部分网页的源码。

import urllib.request
url='ar.com/stock/ranklist_a_3_1_1.html' #目标网址headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64)"} #伪装浏览器请求报头request=urllib.request.Request(url=url,headers=headers) #请求服务器response=urllib.request.urlopen(request) #服务器应答content=response.read().decode('gbk') #以一定的编码方式查看源码print(content) #打印页面源码

虽说抓一页的源码容易,不过在一个网站内大量抓取网页源码却经常遭到服务器拦截,顿时感觉世界充满了恶意。于是我开始研习突破反爬虫限制的功法。
1.伪装流浪器报头
很多服务器通过浏览器发给它的报头来确认是否是人类用户,所以我们可以通过模仿浏览器的行为构造请求报头给服务器发送请求。服务器会识别其中的一些参数来识别你是否是人类用户,很多网站都会识别User-Agent这个参数,所以请求头最好带上。有一些警觉性比较高的网站可能还会通过其他参数识别,比如通过Accept-Language来辨别你是否是人类用户,一些有防盗链功能的网站还得带上referer这个参数等等。
2.随机生成UA
证券之星只需带User-Agent这个参数就可以抓取页面信息了,不过连续抓取几页就被服务器阻止了。于是我决定每次抓取数据时模拟不同的浏览器发送请求,而服务器通过User-Agent来识别不同浏览器,所以每次爬取页面可以通过随机生成不同的UA构造报头去请求服务器,
3.减慢爬取速度
虽然模拟了不同浏览器爬取数据,但发现有的时间段可以爬取上百页的数据,有时候却只能爬取十来页,看来服务器还会根据你的访问的频率来识别你是人类用户还是网络爬虫。所以我每抓取一页都让它随机休息几秒,加入此句代码后,每个时间段都能爬取大量股票数据了。
4.使用代理IP
天有不测风云,程序在公司时顺利测试成功,回寝室后发现又只能抓取几页就被服务器阻止了。惊慌失措的我赶紧询问度娘,获知服务器可以识别你的IP,并记录此IP访问的次数,可以使用高匿的代理IP,并在抓取的过程中不断的更换,让服务器无法找出谁是真凶。此功还未修成,欲知后事如何,请听下回分解。
5.其他突破反爬虫限制的方法
很多服务器在接受浏览器请求时会发送一个cookie文件给浏览器,然后通过cookie来跟踪你的访问过程,为了不让服务器识别出你是爬虫,建议最好带上cookie一起去爬取数据;如果遇上要模拟登陆的网站,为了不让自己的账号被拉黑,可以申请大量的账号,然后再爬入,此处涉及模拟登陆、验证码识别等知识,暂时不再深究...总之,对于网站主人来说,有些爬虫确实是令人讨厌的,所以会想出很多方法限制爬虫的进入,所以我们在强行进入之后也得注意些礼仪,别把人家的网站给拖垮了。
二、所需内容的提取
获取网页源码后,我们就可以从中提取我们所需要的数据了。从源码中获取所需信息的方法有很多,使用正则表达式就是比较经典的方法之一。我们先来看所采集网页源码的部分内容。


为了减少干扰,我先用正则表达式从整个页面源码中匹配出以上的主体部分,然后从主体部分中匹配出每只股票的信息。代码如下。
pattern=re.compile('
body=re.findall(pattern,str(content)) #匹配
stock_page=re.findall(pattern,body[0]) #匹配>和<之间的所有信息
其中compile方法为编译匹配模式,findall方法用此匹配模式去匹配出所需信息,并以列表的方式返回。正则表达式的语法还挺多的,下面我只罗列所用到符号的含义。
语法 说明
. 匹配任意除换行符“\n”外的字符
* 匹配前一个字符0次或无限次
? 匹配前一个字符0次或一次
\s 空白字符:[<空格>\t\r\n\f\v]
\S 非空白字符:[^\s]
[...] 字符集,对应的位置可以是字符集中任意字符
(...) 被括起来的表达式将作为分组,里面一般为我们所需提取的内容
正则表达式的语法挺多的,也许有大牛只要一句正则表达式就可提取我想提取的内容。在提取股票主体部分代码时发现有人用xpath表达式提取显得更简洁一些,看来页面解析也有很长的一段路要走。
三、所得结果的整理
通过非贪婪模式(.*?)匹配>和<之间的所有数据,会匹配出一些空白字符出来,所以我们采用如下代码把空白字符移除。
stock_last=stock_total[:] #stock_total:匹配出的股票数据for data in stock_total: #stock_last:整理后的股票数据
if data=='':
stock_last.remove('')
最后,我们可以打印几列数据看下效果,代码如下
print('代码','\t','简称',' ','\t','最新价','\t','涨跌幅','\t','涨跌额','\t','5分钟涨幅')for i in range(0,len(stock_last),13): #网页总共有13列数据
print(stock_last[i],'\t',stock_last[i+1],' ','\t',stock_last[i+2],' ','\t',stock_last[i+3],' ','\t',stock_last[i+4],' ','\t',stock_last[i+5])
你是如何获得财经方面的消息的?怎么入门了解财经知识?
从人的认知来讲,先从基本的知识来入门比较好。所以这个问题先从后面一部分答。靠谱和权威、专业的入门内容可以从中国证监会、各证券期货交易所、各证券期货基金协会、各大银行、证券、期货公司官网来了解,他们不光有行业的法律法规,更有对应的投资者服务专栏。

比如“中国投资者网”,他是国家专门为投资者服务的证券金融类公益机构,在其网络平台上有诸如基础知识、投资指南、热点关注、风险警示等等各类图文、视频、投教直播内容,让人方便学习了解还贴近实际。

想再深入学习财经知识可以根据个人偏好选择纸质或者电子书来系统学习,比如宏观、微观经济学,这样基本上财经方面的词汇、含义、内容会大致明白。
在这个信息爆炸、消息传播便捷、人人都是信息的发布者和接受者的自媒体时代,各种财经消息是五花八门、良莠不齐,断章取义甚至充当“黑嘴”收割粉丝,所以建议大家在财经消息来源方面还是从官方权威渠道获取,比如人民网、新华网等等,此外各大金融机构的公众号、官网、都会快速发布财经消息和解读。现在手机获取信息很方便,目前看最便捷的还是各金融数据或者证券软件公司的APP,他们的财经数据推送很及时快捷。

此外有深度的财经消息,可以看些知名财经杂志或者人士的文章、视频来做全方位深入了解。
在这个信息时代,知识很多,除了上面说的外,提醒大家了解财经信息要有针对性和目的性,不可贪大求全,不然费神劳力还没效果。还有风险意识要有,不可盲目入市。这里我把想到的说了下,没提到的,欢迎大家补充或私信交流。
怎样能查个人网络金融大数据
如今,国内比较常用的有三种征信数据库。 网贷数据库,百行征信,央行征信。 网贷数据库一般统计那些上征信或者是不上征信的网贷,基本上不上征信的网贷都会上传到网贷数据库。 百行征信统计一些P2P网贷平台的借款数据。 央行征信统计银行与正规网贷的借款数据。 普遍来说,如果想要查询网贷数据报告,那么只需要结合查询网贷数据与央行征信即可。 网贷数据能够直接查看大多网贷平台的数据 微信查找:蓝冰数据。 该数据库与2000多家网贷平台合作,查询的数据相对精准全面。 能够看到用户的申请数据,逾期数据,负债详情,通讯与运营商分析,风险指数分,命中风险提示,法院起诉信息,仲裁案件信息,失信人信息等数据。 其中,用相关文章

4 月三大政策性银行净归还抵押补充
千亿抵押补充贷款“开闸”,保交楼或成为重点投放领域近日,中国人民银行发布公告称,2022年9月,国家开发银行、中国进出口银行、中国农业发展银行净新增抵押补充贷款(简称“PSL”)10
2023-07-23
苏州大学中外合作金融选择4+1,第五
中外合作办学留学项目的学生怎样申请国外的大学?许多人希望用中外合作出国留学完成国外留学的心愿,但一些学生不知道该如何根据中外合作出国留学申请外国大学,下面就给大家解释
2023-07-23
学金融是否可以申到金工、金融科技
我是学金融专业的,想留学读研,请问是否可以转成金融工程专业呢,如果考过GMAT的话可以直接申请吗?理论上是可以的,只要你不介意学校。 找中介代理的话自己会省力很多,可以专心准备G
2023-07-21
平安银行南京分行业务部工作待遇?
平安银行工作的福利待遇怎么样?平安银行工作的福利待遇那是不用说的,我听别人说都是非常好的,他们有六险二金,就是在五险一金的基础上增加了补充医疗保险和年金,在现在这种看病难
2023-07-21
西南财经金融?
西南财经大学金融学专业西南财经大学金融学院金融学专业西南财经大学金融学科在教育部组织的评审中列全国之首,被评为重点学科。顺利通过评审,再次确定为国家重点学科。被评为
2023-07-21
兴业银行因相关工作人员「无证上岗
浦发银行大连分行因原客户经理挪用客户资金等被罚290万,有啥警示作用?浦发银行大连分行因原客户经理挪用客户资金等被罚290万,有啥警示作用首先是警示了银行应该加强监管,其次就
2023-07-21
SVB 金融集团公告称 SVB Capital
风投是什么意思?风投指一切具有高风险、高潜在收益的投资;狭义的风险投资是指以高新技术为基础,生产与经营技术密集型产品的投资。从投资行为的角度来讲,风险投资是把资本投向蕴
2023-07-21
上海成立首个总行级科技金融事业部
金融科技对金融行业有什么影响?金融科技对商业银行的影响是比较大的。 1.利:时代不断在进步,社会生活的节奏在持续加快,许多行业的竞争在加大,商业银行已不能完全依靠传统方式来
2023-07-19
我是做金融贷款的,应该怎么寻找优质
做金融怎么找客户当下,金融贷款行业越来越竞争激烈,如何获得客户成为了每一家金融机构面临的重要问题。那么,除了电销,金融贷款行业还有哪些获客方法呢?本文将从社交媒体、内容营
2023-07-19
金融加教育有什么毕业论文选题吗?
2021年金融专业,推荐的论文选题有哪些啊,哪些是比较好写的?都是比较好写的,如下:一、国际金融问题1、国际资本流动与金融危机2、金融危机传染与发展中国家的防御3、新兴市场经
2023-07-19